

Delta Lake has been an absolute pleasure to work with for the last couple of years, and it solved plenty of ongoing issues with data lakes using the Delta file format. Now it becomes more powerful in its third version and evolution.
Databricks recently announced the 3.0 version of the Delta Lake and Delta files, and in this article, we're going to look at what version 3.0 brings in this new iteration. I'm also hoping to create an example of how Delta Lake 3.0 works in the upcoming weeks, to demonstrate these new capabilities. I'm especially excited about UniForm.
Delta Universal Format (UniForm)
Delta files are powering Delta Lakes all over the globe, adding capabilities of databases to the traditional data lakes. Never mind the ACID transaction support, the MERGE capability alone is a powerful add-on to a plain Parquet-based lakes. It wasn't alone in making data lakes a better place, however; Apache Hudi and Apache Iceberg have been contributing to the ecosystem, too. But as usual, multiple competing file formats cause interoperability issues, requiring clients to support not just Delta files, but also Hudi and Iceberg files.
Delta Lake 3.0 brings a solution to this problem: The Delta engine will now generate the necessary metadata for Hudi and Iceberg files under the hood, so when you write with Delta, it can be read by any other client that supports those formats.
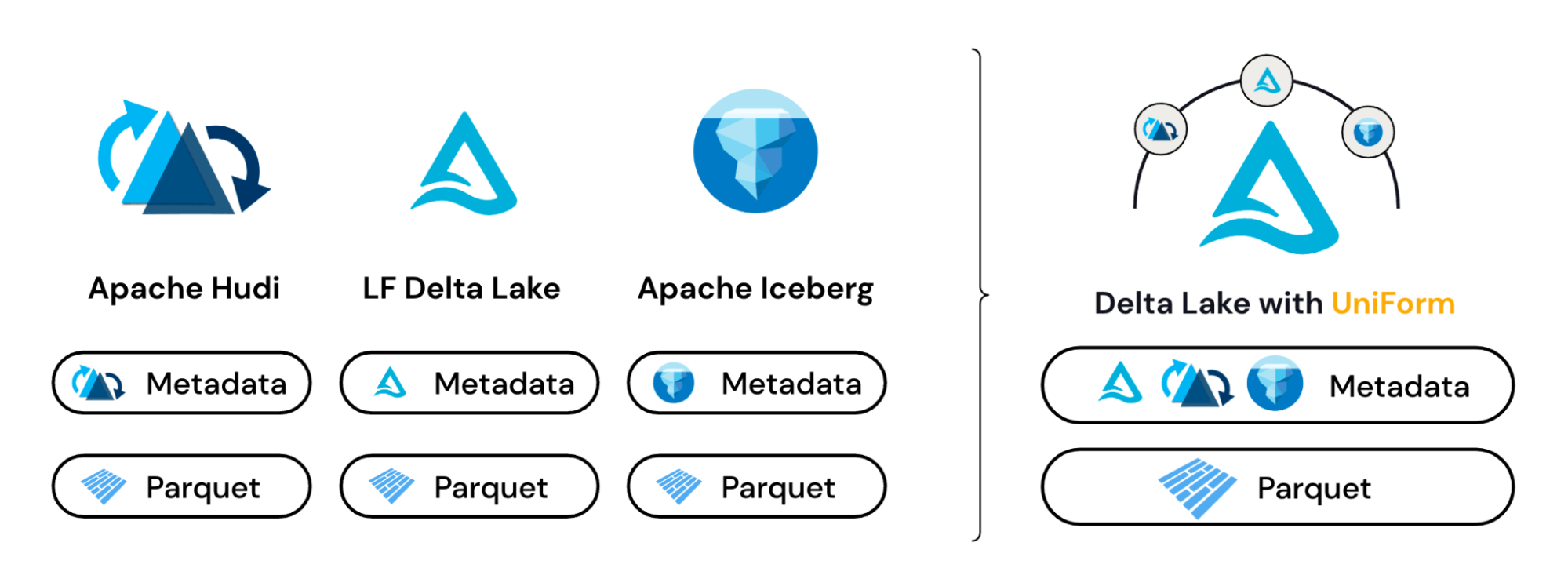
What's the benefit, you ask? Think it like this: You want to purchase a third-party tool that has the support for Apache Hudi and Apache Iceberg, as they are, well, Apache Foundation technologies. But you have invested so much into Delta Lake that you don't want to generate the same data files on your layers that's already there as Delta files. Solution? Delta Lake 3.0 will generate the necessary metadata for those files to be easily read and queried by your potential new purchase.
Does this mean that Iceberg and Hudi adapters will support this UniForm format? Not right now. It'll require the Apache Foundation to play along and support the same metadata generation process. Currently, it's read-only from Hudi and Iceberg side.
Delta Kernel
It also has been a pain to keep the connector extensions in sync for support of the Delta format, as each platform runs on a different application runtime and language. That requires the Delta protocol to be re-implemented in each runtime, and kept regularly updated.
Delta Kernel solves this by acting as middle-ground by wrapping the under-the-hood Delta operations in a set of Java libraries that can read from (and according to their website, write to, soon) Delta tables, without requiring the connectors to make a detailed implementation. This would allow the ecosystem to adopt Delta Lakes faster, as it won't require them to know how Delta works under the hood. It'll act as a framework that abstracts the platforms from Delta's inner workings.
Liquid Clustering
As the databases suffered from changing queries and requirements for as long as they existed, Delta Lakes suffer the same fates. You may create your tables with certain partitioning in mind to respond to today's query requirements fast, but it probably won't be as fast in the future when the clients start querying the data in various other ways.
Liquid Clustering brings a solution to the table by dynamically adjusting the partitioning based on the data patterns. According to Databricks, this would help avoid over-partitioning and under-partitioning that happens with Hive.
It's easy and straightforward to implement, but I'm yet to see it in action to make up my mind. In my experience, nothing dynamic works without any supervision. So, we'll see soon how good this promise is.
Further Reading

.png)
 delta-iodelta-io
delta-iodelta-io