

Fabric extends the Power BI workspaces with more item types, but those workspaces come with a lot of baggage. If you're coming from Azure Synapse Analytics or Data Factory, it may not be easy to figure out how to utilise workspaces best. We'll dive into it in this article.
Microsoft made an excellent design decision to extend Power BI workspaces when building Fabric, as it had been in use for a long time, and they have almost perfected during the Power Platform's evolution. A Power BI workspace allows users to import their data, process it, crunch it, and visualise it. Now with Fabric, It contains your pipelines, notebooks, lake houses, warehouses, KQL databases, etc., for you to create value within the boundaries of your workspace.
Workspaces are access-controlled, so only people & apps with valid credentials and permissions can access them. If Fabric were a hotel, workspaces would be the rooms. It comes with a bed, a desk, a chair, air conditioning, etc., for you to get comfortable. It's only accessible by the key cards issued for that room. You can decorate it as you wish during your stay, and it's maintained and cleaned.
But, if you're coming from Azure Synapse Analytics or Data Factory, you may not feel at home when using Fabric. It may be difficult for you to find your way around workspaces initially.
Workspaces Can Become Messy
If you are an experienced Power BI user or a BI engineer, you know how the workspaces can become overly crowded and messy, like a prison. The promise of workspaces might be "structure as you want", but that doesn't tend to fly in real-world scenarios. Why? It invites chaos. And end-users. Mostly end-users.
If there isn't an upfront design, even an outline, engineers and end-users can quickly fill the workspace with the data they want, regardless of whether it makes sense. The PII data might become commonplace, and with the bloated sharing permissions, it might turn into a ticking time bomb. That kind of workspace clutter can give even Marie Kondo a stroke, let alone your cybersecurity team.
Monitoring system-level jobs and processes is also problematic when there's so much user interference. You may set up a lakehouse and its dataset to expose data to another workspace, but an end user might come in and delete that dataset because they think it's not used any more.
Okay, enough bashing the end-users. We have a love/hate relationship with them. That's how we get paid. Let's talk about how we can design workspaces in a way that would create fewer issues and more value.
Separating System-Level Workspaces from User-Level Ones
Let's discuss an imaginary scenario: You want to bring data from your order system to your Fabric tenant, but the integration works through an overnight file transfer. You also want to validate this file, check for any discrepancies, and raise an alert automatically if something is wrong. You want this data to be available to the BI engineers and end-users via a proper schema and read-optimised queries.
Even from the paragraph above, you must've deduced that importing this dataset into an existing user-level Power BI workspace (upgraded to use Fabric) won't work. There's just too much chaos to handle there. Then, what?
The solution is to separate this kind of process from user workspaces and create System-Level Workspaces to work in a more deterministic way.

You can create a new workspace for your Order system and embed this process there. The consumers (users and apps) don't need to know how you brought the data into the workspace, what kind of validations you did, and the intermediary steps to achieve that goal. They need to have access to the data.
And you can wrap all your Pipelines, Data Flows, Notebooks, ML Models, etc., with your workspace boundaries and only give permission to your consumers on the lakehouse level. That way, they can query it via its SQL endpoint or link the underlying OneLake files to their workspace using Shortcuts.
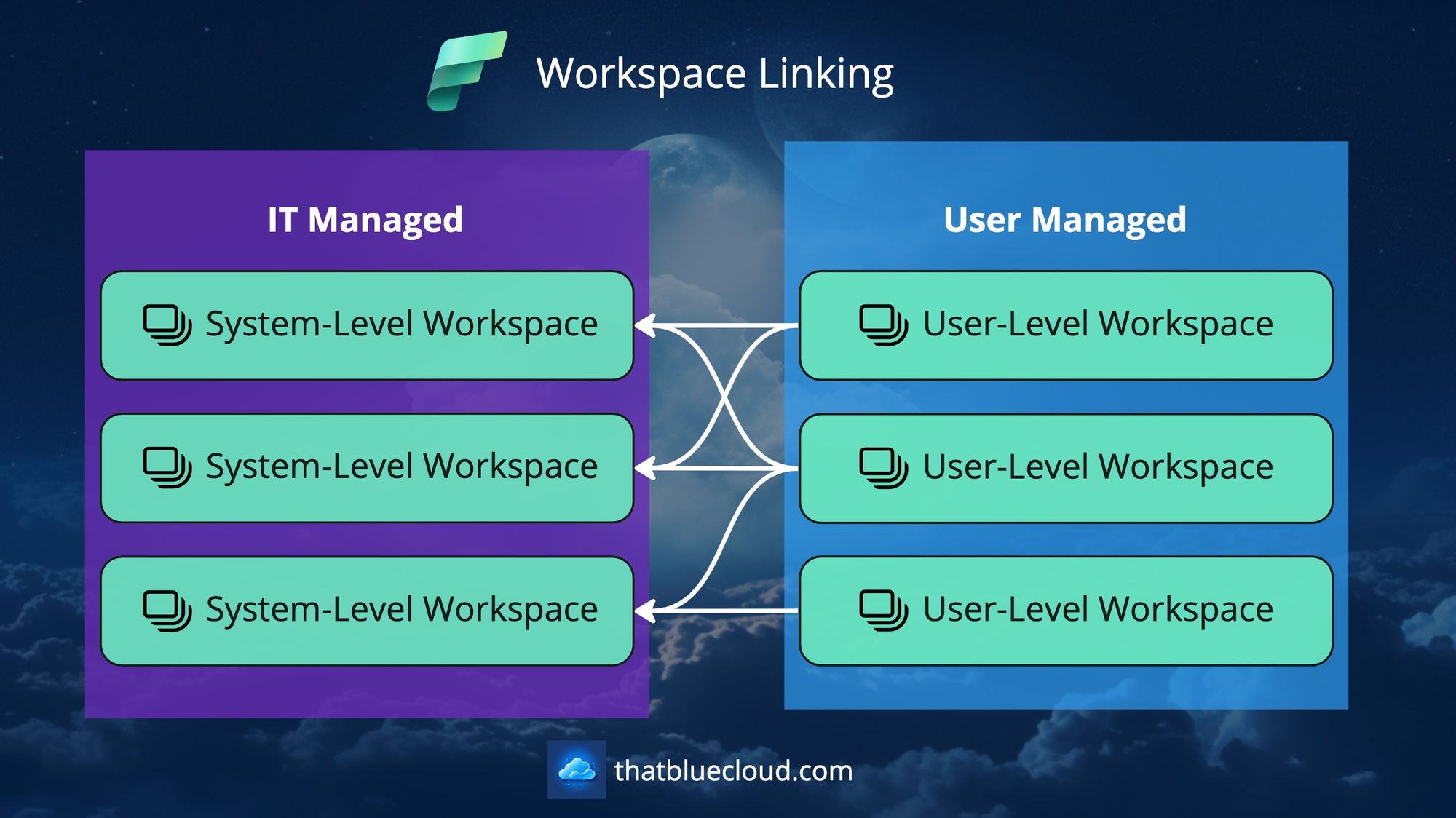
You can also integrate this System-Level Workspace with your source control and the CI/CD process. Fabric's deployment pipeline process currently only works with Power BI artefacts, but surely that feature will be available for all item types in the near future. That way, you can have a Dev workspace to work on and promote your changes to the Prod workspace as needed.
Not sure how to come up with a high-level design to achieve all this? Why not adopt Medallion Architecture?
Use Medallion Architecture For Designing System Workspaces
Medallion Architecture can act as a starter template here. It contains the structure to power lakehouses and warehouses with a good number of layers and processes, so it can help you to create at least some order in all that chaos to come. Briefly, Medallion asks you to have three layers of data when ingesting and processing data:
- Bronze/Raw: A layer for incoming data to be kept and archived for access. You keep the data format as it comes (JSON, CSV, etc.) and store them in a hierarchy to access them easily (most commonly, date of arrival and data type are used in folder structure).
- Silver/Trusted: Raw data is translated into a more standardised format. You can split a single raw file into multiple files/tables to create a normalised relationship, or you can put together multiple raw files into a single table. Best suitable for Delta files.
- Gold/Curated: Business-level aggregations and analytics are stored here. It can also host the data that ships out of your Lakehouse.
If you apply Medallion Architecture to Fabric, this is how it would look like:
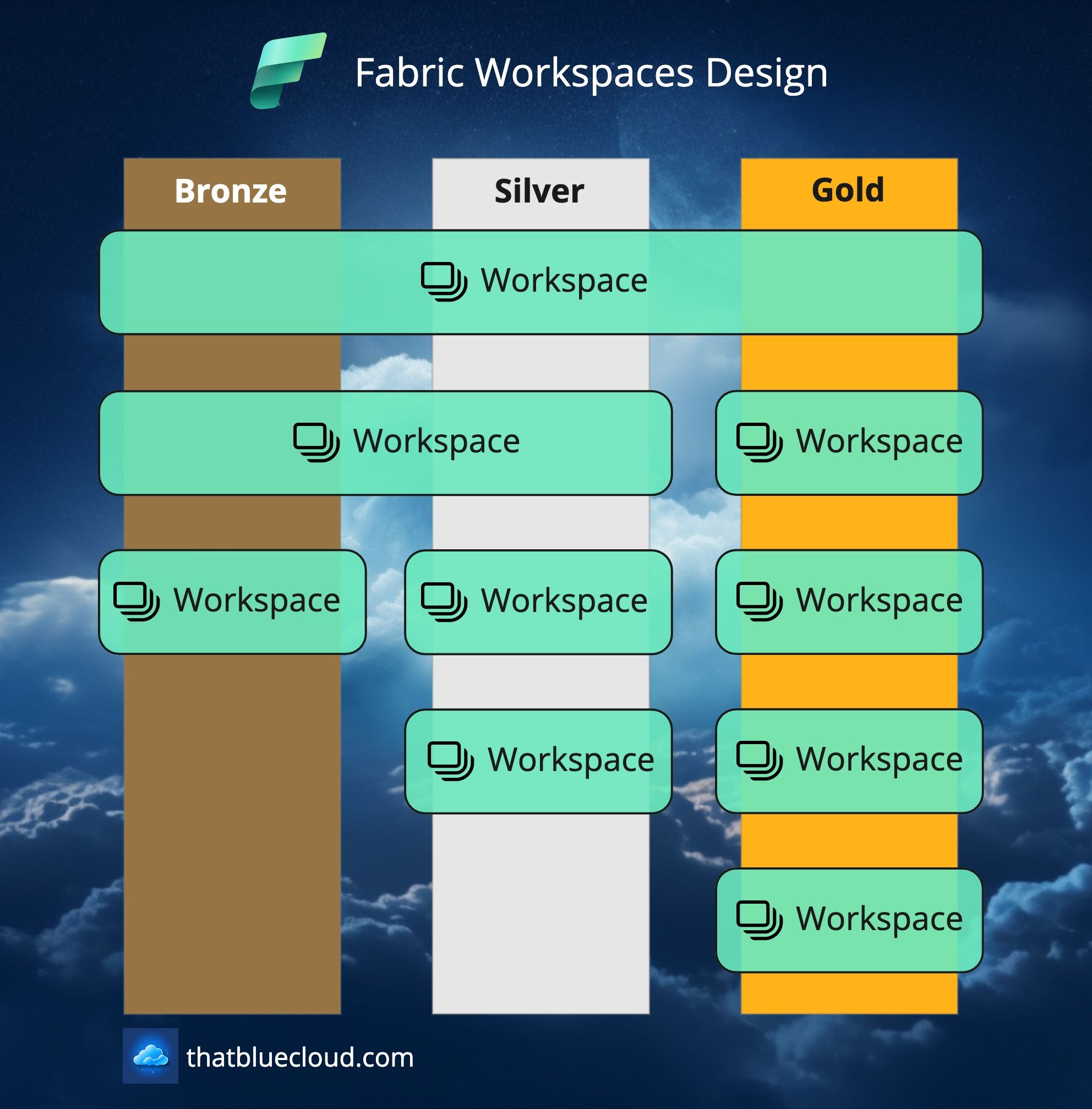
Depending on your complexity, you have the option to separate your workspaces as below:
- Bronze, Silver, and Gold in a single Workspace: Nothing prevents you from creating a single workspace that encompasses all three layers. You can even create a single Lakehouse and handle the separation within your single Lakehouse. Beware, though: Permissions in Fabric are not granular enough to assign separate permissions for separate tables or files within your Lakehouse. Until that support arrives, think that a single key can provide access to every room in the hotel.
- Bronze and Silver in the same Workspace: This might work better for most use cases. Unless you need to keep people away from your raw data (for security or privacy reasons), a single lakehouse in a single workspace might make things granular enough but manageable, allowing you to tackle things easily. This would also allow you to create Source-based or Domain-based Workspaces to create better vertical segregation.
- Bronze, Silver and Gold, each in separate Workspaces: This would allow you to have the most flexibility but also the most complexity. You could grant permissions on each level for each source, ensure only necessary things are exposed from their encapsulations/workspaces, and keep better lineage. But it'll come at the cost of increased complexity and management overhead. Use this option sparingly and only when necessary.
- Silver-Only Workspaces: When you want to encapsulate a particular domain, it may not map directly to a source system or any other existing Silver workspaces. Nothing is preventing you from doing this, as long as you respect the responsibilities of the Silver layer and don't abuse it.
- Gold-Only Workspaces: The most common ones will be these Workspaces. Business teams or BI teams can create it, and it can create multiple data products that depend on the Silver layer Workspaces and uses them to generate value and insights.
Here's how it would look like in a bit more detail:
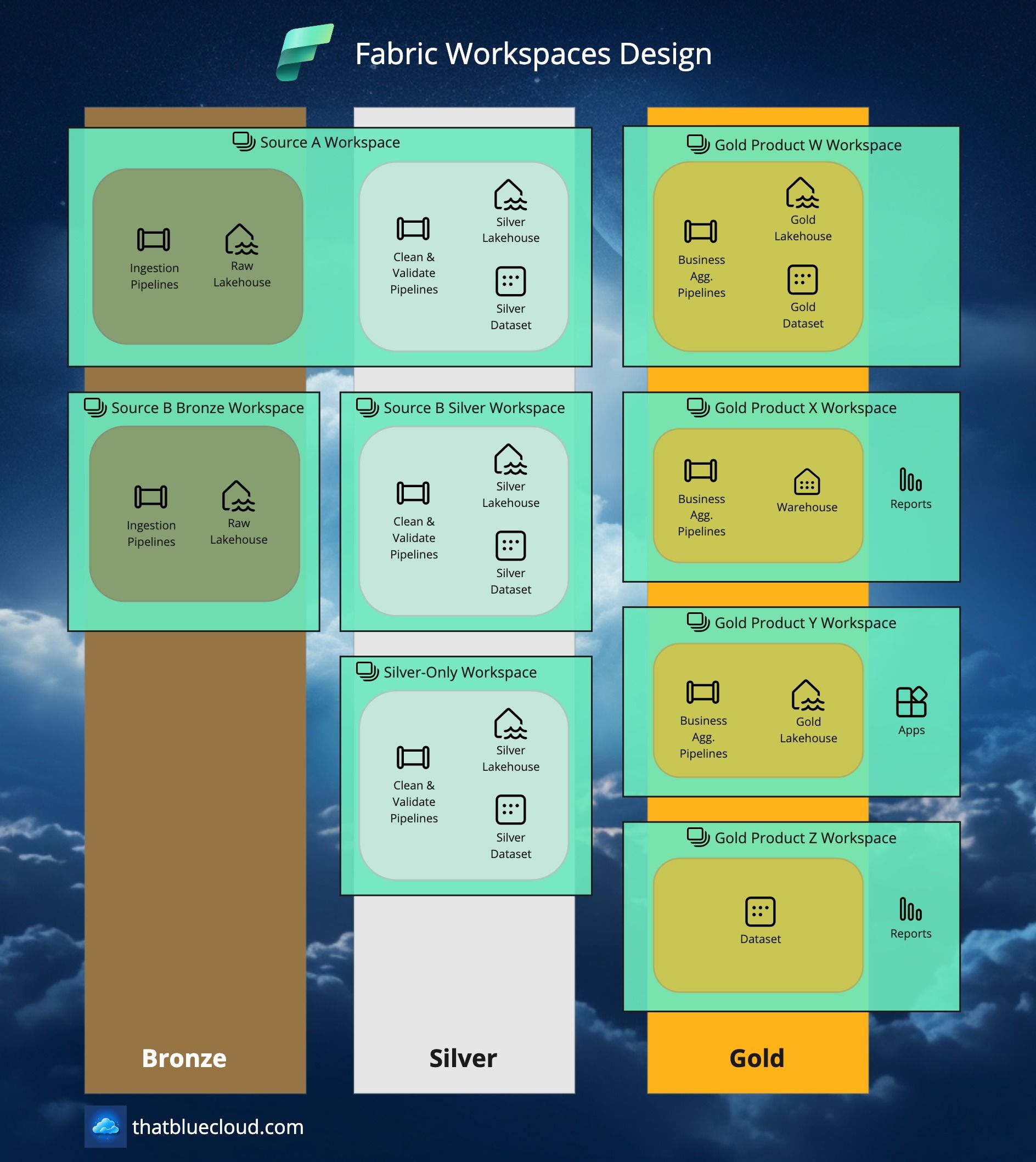
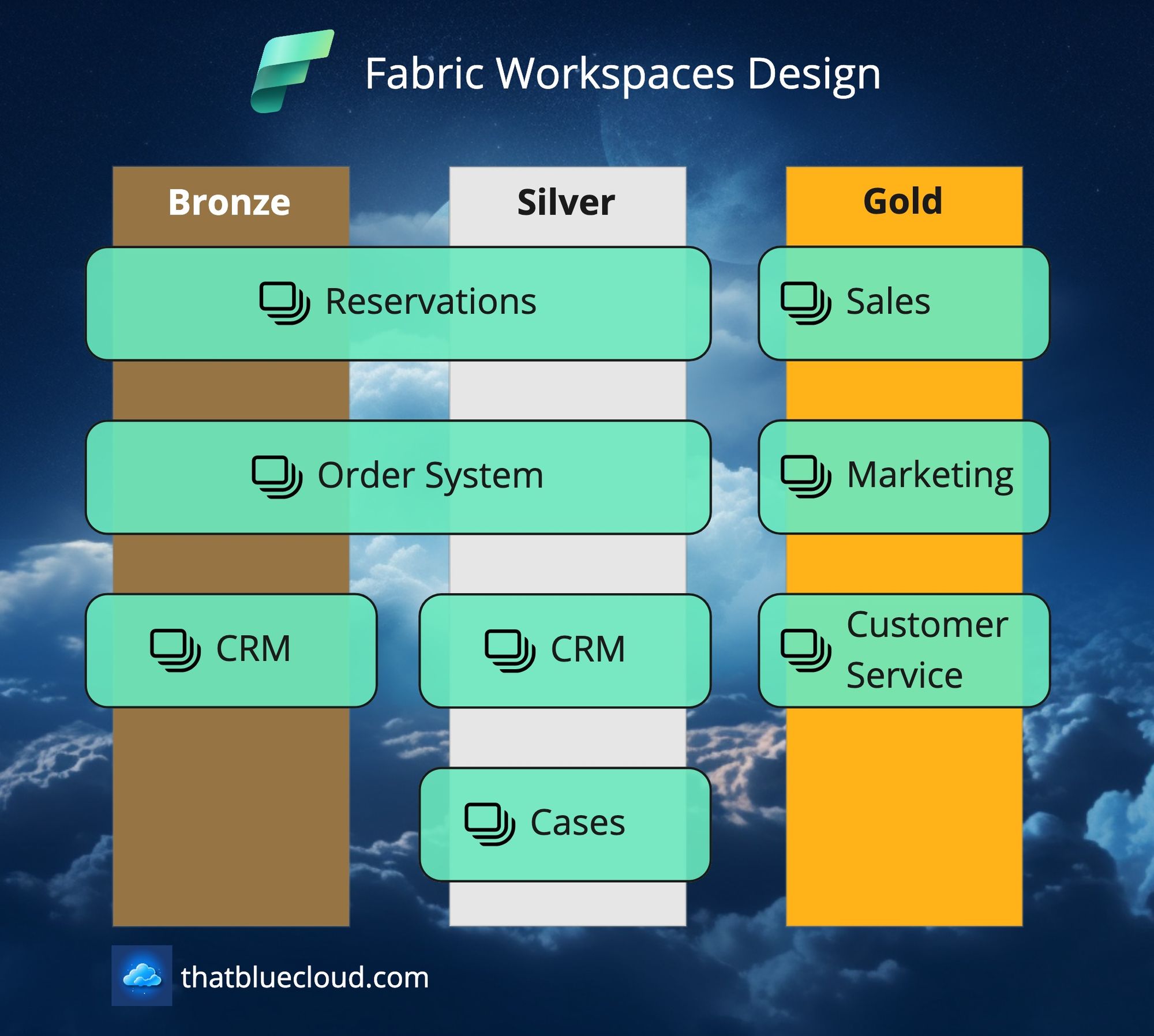
When designing your Workspace landscape, imagine it like a matrix. You have two axes: Horizontal (layers like Bronze, Silver and Gold) and Vertical (source systems or data products). When you're only interested in ingesting data from a source system and making it available for further use, you will have only Bronze and Silver on the horizontal axis for that source system, which is on the vertical axis. I know it's a bit confusing, let me show it in an example:
Conclusion
All in all, designing workspaces is not rocket science. The entire idea and promise behind this architecture is to have defined layers and responsibilities, so you would know how to ingest a new data source properly or know where to look for data when you're trying to create insights.
