

TL;DR:Lakehouses are basically Data Warehouses built on top of Data Lakes using primarily Spark-based data processing technologies.
That’s it. That’s what a Lakehouse does. You’ll see a lot of online content talking about Lakehouses like they are some sort of alien technology that’s either supposed to save us or destroy us. With the arrival of Microsoft Fabric, which is a combination of Synapse Workspaces, Dataverse and PowerBI Workspaces, it looks even more out-of-this-world. It isn’t. Yes, Lakehouses make the data processing, reporting, and analytics a breeze, but there’s nothing groundbreaking about them.
The primary use case of the Lakehouse Architecture is to combine your data to gain insights and value out of it, the same way you would build a Warehouse, using the same patterns and practices. Instead of copying your data for the Nth time from your Data Lake to your Warehouse, you achieve it by bringing your computation engine on top of your Lake. The real disruptive parts (where the actual magic happens) behind Lakehouses are two technologies: Data Lakes and Delta Lakes.
Lakehouses bring you the best of two worlds: Data Lakes and Data Warehouses. It’s true, the word “Warehouse” is very much loaded these days and became a slang for “unnecessarily big datastore, doomed from day one”. And I agree. I’ve seen my fair share of failed Warehouse projects. But you have to remember, there’s a reason why they were invented in the first place, and why they were disruptive many (many!) years ago: You had to put your data together in a structured way to ask (and shall receive) bigger questions, like “How was my sales trend in the past six months compared to the internet traffic our website received in the same timeframe?”.
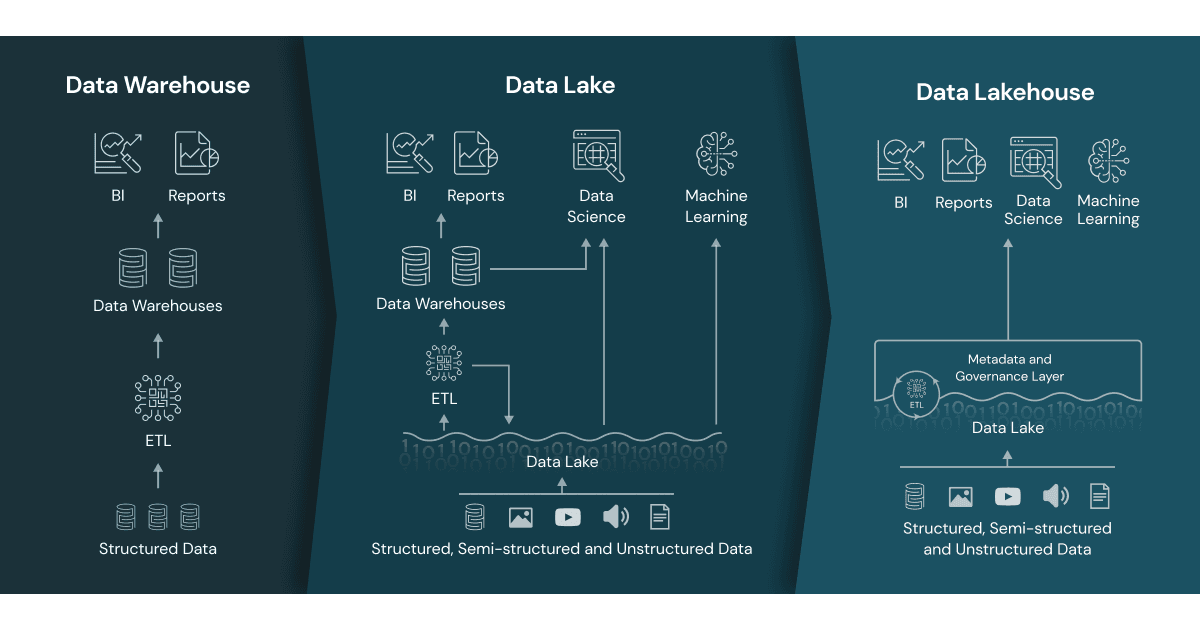
Now, you can answer those questions (and beyond) much easier with the Lakehouses. They are easier to build, cost less, easier to maintain, and offer much more integration possibilities with other technologies.
Why Use a Lakehouse?
Lakehouse architecture gives you the best of two worlds: You can have a Data Lake with both batched and streaming data flowing in, and you can gain insights from that data without pumping it to a Data Warehouse again. You can have both analytics and insights from your data without moving it.
- Lakehouse would allow you to introduce different clusters to process your data based on your scenarios.
- You can optimise the costs by combining multiple types of clusters with short bursts, rather than having a single compute engine that can only scale up or down.
- You can still primarily use SQL as your language and define Tables and Views based on your Delta Lake
- You can enrich that pipeline with Python, Scala & R and benefit from those languages’ own ecosystems as well.
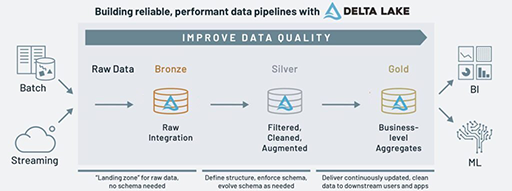
When to use a Lakehouse?
Favour building a Lakehouse over a Warehouse when:
- You have a Data Lake that you have invested in
- You have requirements to support not just structured data, but also to support semi-structured and unstructured data scenarios
- You have requirements for not just data analytics, but also data science and machine learning
- You want to have your insights accessible from other apps and not stay in an isolated database/warehouse environment
- You have requirements to include both batched and streaming data in your ecosystem
- You aim to have a hybrid ecosystem that can support multiple use cases that warehouses can’t
- You intend to process your data without needing to move it out of the lake
When to use a Warehouse?
Favour building a Warehouse when:
- You don’t have the time or the desire to invest in a Data Lake.
- You have a very specific requirement that would need you to utilise a very mature Data Warehousing engine to solve it.
- You have a very specific Warehouse-oriented skillset in your company that you can’t retrain or renovate.
Conclusion
Warehouses are not going anywhere. They are still around, and they are still one of the best ways to solve your analytics problems. But they are clunky, hard to maintain and costly. They begin to have performance issues not long after they are built as they tend to attract other requirements and business apps as warehouses tend to have high-quality data. Usually, the solution is to “throw more money at it”.
Whilst Warehouses are monolithic and keep the data isolated, Lakehouses are more modular and have an open approach. Rather than having a big Warehouse that would receive hundreds of questions it can’t answer, you can have more than one Lakehouse cluster that each would answer less questions but give quality answers.
If you’re just starting your data analytics journey, or you’re looking to replace your old and clunky warehouse, I strongly suggest choosing Lakehouse as your new approach. The industry has moved on from isolated databases towards Data Lakes, and the ecosystem has developed so much that you feel comfortable with Lakehouses as you would at home (if you’ve been living in a warehouse, of course).
At the very least, you’ll be growing a data lake that would allow you to adopt newer and better technologies in the future. That’s something that warehouses never promised.
