

As mentioned before, Databricks announced the v3.0 of Delta Lake. Apart from the bells and whistles, it has one powerful feature: Support for Apache Hudi and Iceberg. Although it looks like a compensational feature on Databricks’ behalf, when used in the right place, the support for Hudi and Iceberg can unlock many opportunities.
Let’s go through an example, as is my usual: Most companies start small and grow by implementing the new requirements by replicating what’s already there. If you started your Delta Lake with a Medallion Architecture, you would have all your raw data from sources coming into your Raw/Bronze area. You may create a few generic Azure Data Factory pipelines and data flows that you just configure with different parameters to validate this raw data and put into your Silver zone with Delta format. These generic pipelines might validate post codes, normalise the casing of first name and last names, even split your PII data into a secure area and reference it in the Trusted/Silver zone.
But when you grow further and introduce more teams and personas to your lake, you’ll quickly realise that not everything supports the Delta format. You will find yourself publishing different versions of the same file, just to keep interoperability intact. One business team might purchase a new tool that works brilliantly with Apache Iceberg, but not with Delta.
If you upgrade your engine to use Delta 3.0 (or Microsoft does with ADF Data Flows), the Silver zone data can be easily consumed by that new tool. You wouldn’t need to implement a separate logic to support that new product. By default, a simple upgrade would unlock new opportunities for you.
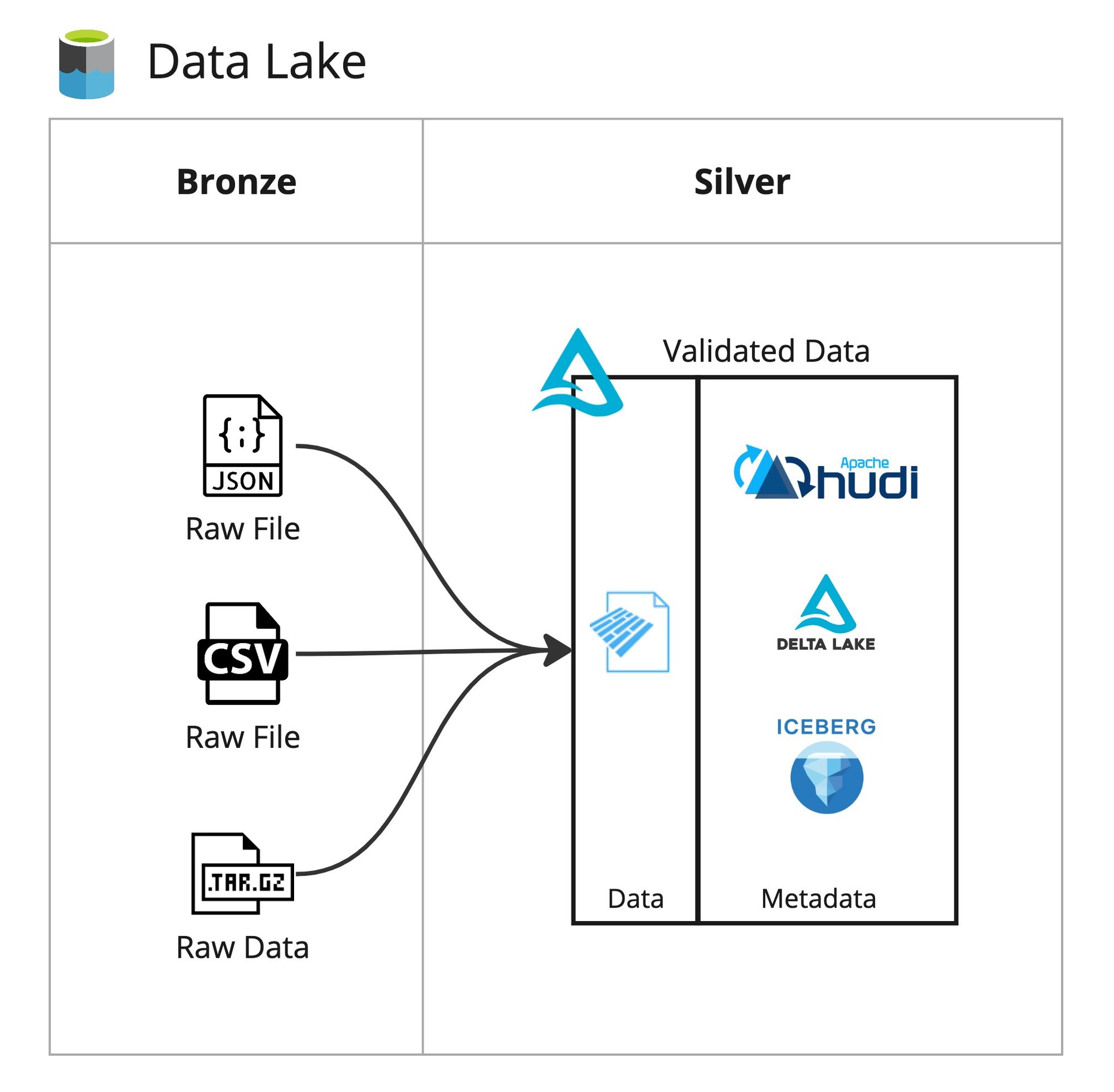
This same benefit can be had when reading from the Gold layer as well. When Microsoft Fabric starts supporting Delta 3.0, all your data generated by your Gold Lakehouses in your Fabric workspaces can be easily read by Apache Hudi or Iceberg compatible engines. All you have to do is to refresh your data files, and Bob’s your uncle. That pesky reporting tool you bought that didn’t support Delta files, but supports Apache formats? That’ll work right out of the box.
Whilst the Delta file format has a very high adoption rate in the industry, many companies are hesitant to invest in it because Databricks still is the maintainer of the Delta format. True, it’s open source, but it doesn’t mean the vendor won’t change the roadmap of Delta format in the future where it won’t be as compatible as it is now. Many companies would sway in favour of Apache technologies, and the adoption of Hudi and Iceberg will grow exponentially.
And whilst Delta could still power your data pipelines, there’s nothing wrong unlocking new opportunities with some other open-source technologies.
